```{r setup, include=FALSE}
opts_chunk$set(cache=TRUE)
```
Web Scraping part 3: Scaling up
========================================================
width: 1200
author: Rolf Fredheim and Aiora Zabala
date: University of Cambridge
font-family: 'Rockwell'
04/03/2014
Catch up
==================
Slides from week 1: http://quantifyingmemory.blogspot.com/2014/02/web-scraping-basics.html
Slides from week 2: http://quantifyingmemory.blogspot.com/2014/02/web-scraping-part2-digging-deeper.html
Today we will:
========================================================
- Revision: loop over a scraper
- Collect relevant URLs
- Download files
- Look at copyright issues
- Basic text manipulation in R
- Introduce APIs (subject of the final session)
Get the docs:
http://fredheir.github.io/WebScraping/Lecture3/p3.html
http://fredheir.github.io/WebScraping/Lecture3/p3.Rpres
http://fredheir.github.io/WebScraping/Lecture3/p3.r
Digital data collection
=======================
- **Devise a means of accessing data**
- Retrieve that data
- **tabulate and store the data**
Today we focus less on interacting with JSON or HTML; more on automating and repeating
Using a scraper
===============
 In code
===================
Remember this from last week?
```{r}
bbcScraper <- function(url){
SOURCE <- getURL(url,encoding="UTF-8")
PARSED <- htmlParse(SOURCE,encoding="UTF-8")
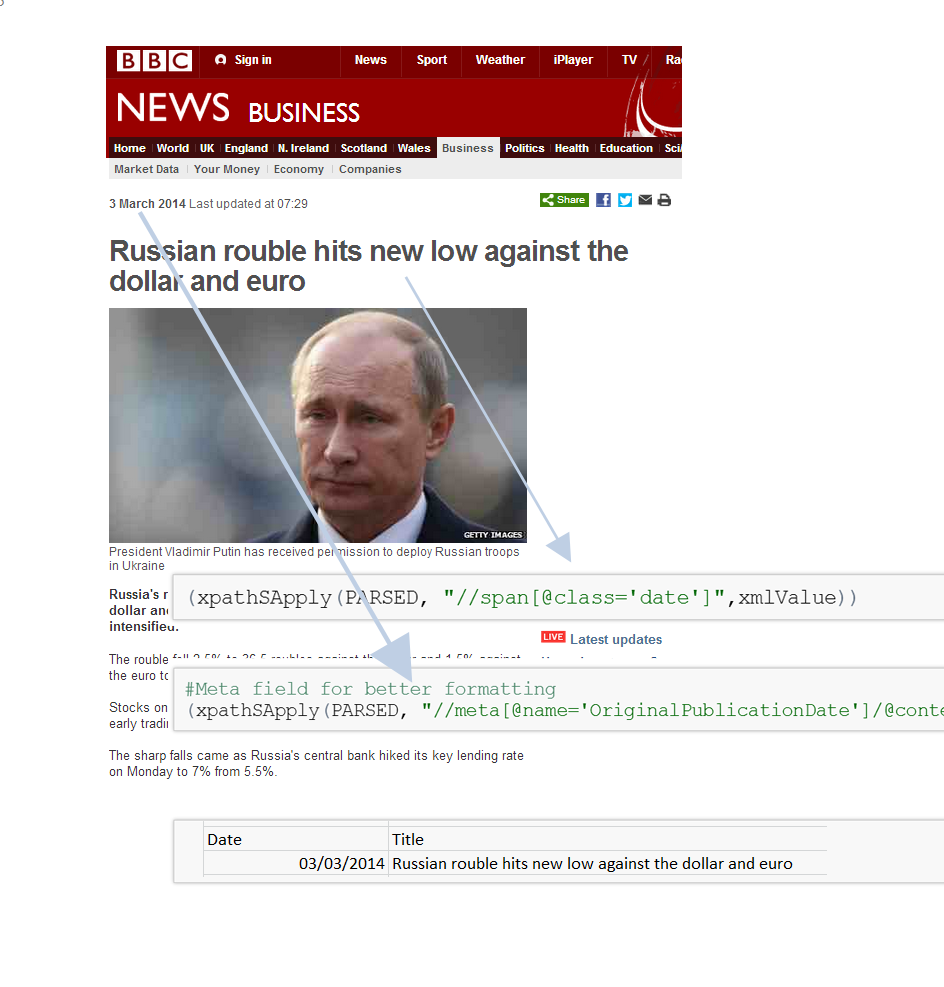
title=xpathSApply(PARSED, "//h1[@class='story-header']",xmlValue)
date=as.character(xpathSApply(PARSED, "//meta[@name='OriginalPublicationDate']/@content"))
if (is.null(date)) date <- NA
if (is.null(title)) title <- NA
return(c(title,date))
}
```
We want to scale up
======================
In code
===================
Remember this from last week?
```{r}
bbcScraper <- function(url){
SOURCE <- getURL(url,encoding="UTF-8")
PARSED <- htmlParse(SOURCE,encoding="UTF-8")
title=xpathSApply(PARSED, "//h1[@class='story-header']",xmlValue)
date=as.character(xpathSApply(PARSED, "//meta[@name='OriginalPublicationDate']/@content"))
if (is.null(date)) date <- NA
if (is.null(title)) title <- NA
return(c(title,date))
}
```
We want to scale up
======================
 How?
============
- Loop and rbind
- sapply
- sink into database
sqlite in R: http://sandymuspratt.blogspot.co.uk/2012/11/r-and-sqlite-part-1.html
Loop
==============
type:sq
```{r}
require(RCurl)
require(XML)
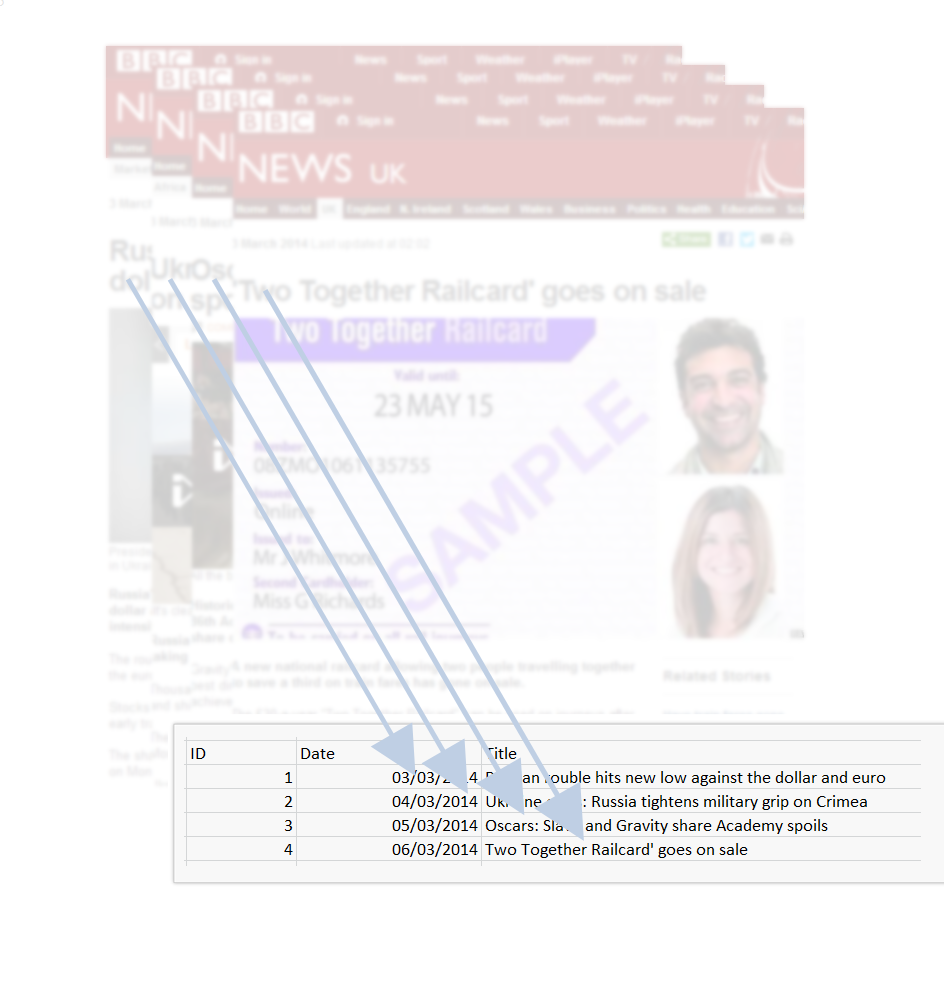
urls <- c("http://www.bbc.co.uk/news/business-26414285","http://www.bbc.co.uk/news/uk-26407840","http://www.bbc.co.uk/news/world-asia-26413101","http://www.bbc.co.uk/news/uk-england-york-north-yorkshire-26413963")
results=NULL
for (url in urls){
newEntry <- bbcScraper(url)
results <- rbind(results,newEntry)
}
data.frame(results) #ignore the warning
```
Still to do: fix column names
Disadvantage of loop
=====================
type:sq2
left:80
copying data this way is inefficient:
```{r}
temp=NULL
#1st loop
temp <- rbind(temp,results[1,])
temp
#2nd loop
temp <- rbind(temp,results[2,])
#3d loop
temp <- rbind(temp,results[3,])
#4th loop
temp <- rbind(temp,results[4,])
temp
```
=============
In each case we are copying the whole table in order to add a single line.
- this is slow
- need to keep two copied in memory (means we can only ever use at most half of computer's RAM)
sapply
===========
A bit more efficient.
Takes a vector.
Applies a formula to each item in the vector:
```{r}
dat <- c(1,2,3,4,5)
sapply(dat,function(x) x*2)
```
syntax: sapply(data,function)
function: can be your own function, or a standard one:
```{r}
sapply(dat,sqrt)
```
in our case:
========================
type:sq
```{r}
urls <- c("http://www.bbc.co.uk/news/business-26414285","http://www.bbc.co.uk/news/uk-26407840","http://www.bbc.co.uk/news/world-asia-26413101","http://www.bbc.co.uk/news/uk-england-york-north-yorkshire-26413963")
sapply(urls,bbcScraper)
```
we don't really want the data in this format. We can reshape it, or use a related function:
=================
ldply: For each element of a list, apply function then combine results into a data frame.
```{r}
require(plyr)
dat <- ldply(urls,bbcScraper)
dat
```
Task
===============
type:section
- Scrape ten BBC news articles
- Put them in a data frame
Link harvesting
====================
Entering URLs by hand is tedious
We can speed this up by automating the collection of links
How can we find relevant links?
- ?
- Scraping URLs in a search result
- those on the front page
Search result
============
Go to page, make a search, repeat that query in R
Press next page to get pagination pattern. E.g:
http://www.bbc.co.uk/search/news/?page=2&q=Russia
Task
==========
type:section
Can you collect the links from that page?
Can you restrict it to the search results (find the right div)
One solution
================
type:sq1
All links
```{r results="hide"}
url="http://www.bbc.co.uk/search/news/?page=3&q=Russia"
SOURCE <- getURL(url,encoding="UTF-8")
PARSED <- htmlParse(SOURCE)
xpathSApply(PARSED, "//a/@href")
```
filtered links:
```{r results="hide"}
unique(xpathSApply(PARSED, "//a[@class='title linktrack-title']/@href"))
#OR xpathSApply(PARSED, "//div[@id='news content']/@href")
```
Why 'unique'?
Another option: xpathSApply(PARSED, "//div[@id='news content']/@href")
Create a table
=====================
type:sq1
```{r}
require(plyr)
targets <- unique(xpathSApply(PARSED, "//a[@class='title linktrack-title']/@href"))
results <- ldply(targets[1:5],bbcScraper) #limiting it to first five pages
results
```
Scale up further
==============
Account for pagination by writing a scraper that searches:
http://www.bbc.co.uk/search/news/?page=3&q=Russia
http://www.bbc.co.uk/search/news/?page=4&q=Russia
http://www.bbc.co.uk/search/news/?page=5&q=Russia
etc.
hint: use paste or paste0
Let's not do this in class though, and give the BBC's servers some peace
Copyright
======================
type:sq
Reading
- http://about.bloomberglaw.com/practitioner-contributions/legal-issues-raised-by-the-use-of-web-crawling-and-scraping-tools-for-analytics-purposes/
- http://www.theguardian.com/media-tech-law/tangled-web-of-copyright-law
- http://matthewsag.com/googlebooks-decision-fair-use/
- http://www.bbc.co.uk/news/technology-26187730
- http://matthewsag.com/anotherbestpracitcescode/
- http://www.ipo.gov.uk//response-2011-copyright-final.pdf
- http://www.arl.org/storage/documents/publications/code-of-best-practices-fair-use.pdf
> One case involved an online activist who scraped the MIT website and ultimately downloaded millions of academic articles. This guy is now free on bond, but faces dozens of years in prison and $1 million if convicted.
===================
> PubMed Central UK has strong provisions against automated and systematic download of articles: Crawlers and other automated processes may NOT be used to systematically retrieve batches of articles from the UKPMC web site. Bulk downloading of articles from the main UKPMC web site, in any way, is prohibited because of copyright restrictions.
--http://www.technollama.co.uk/wp-content/uploads/2013/04/Data-Mining-Paper.pdf
Rough guidelines
=======================
type:sq
I don't know IP law. So all the below are no more than guidelines
Most legal cases relate to copying and republishing of information for profit (see article1 above)
- Don't cause damage (through republishing, taking-down servers, prevention of profit)
- Make sure your use is 'transformative'
- Read the TOCs
In 2013 Google Books was found to be 'fair use'
- Judgement good news for scholars and libraries
Archiving and downloading
- databases can be used to 'facilitate non-consumptive research'
Distinction made between freely available content, and that behind a pay-wall, requiring to accept conditions, etc.
Downloading
===========
type:sq
Don't download loads of journal articles. Just don't
If you need/want to download something requiring authentication, be careful.
-attach cookie
Packages: httr
Many resources on how to do this, many situations in which this is totally OK. It is not hard, but often quite shady. If you need this for your work, consider the explanations below, and exercise restraint.
- http://stackoverflow.com/questions/13204503
- http://stackoverflow.com/questions/10213194
- http://stackoverflow.com/questions/16118140
- http://stackoverflow.com/questions/15853204
- http://stackoverflow.com/questions/19074359
- http://stackoverflow.com/questions/8510528
- http://stackoverflow.com/questions/9638451
- http://stackoverflow.com/questions/2388974
Principles of downloading
=====================
Function: download.file(url,destfile)
destfile = filename on disk
option: mode="wb"
Often files downloaded are corrupted. Setting mode ="wb" prevents "\n" causing havoc, e.g. with image files
Example
===============
http://lib.ru
Library of Russian language copyright-free works. (like Gutenberg)
This is a 1747 translation of Hamlet into Russian
Run this in your terminal:
```{r, eval=F}
url <- "http://lib.ru/SHAKESPEARE/hamlet8.pdf"
download.file(url,"hamlet.pdf",mode="wb")
```
navigate to your working directory, and you should have the pdf there
Automating downloads
=================
type:sq1
As with the newspaper articles, downloads are facilitated by getting the right links. Let's search for pdf files and download the first ten results:
```{r}
url <- "http://lib.ru/GrepSearch?Search=pdf"
SOURCE <- getURL(url,encoding="UTF-8") # Specify encoding when dealing with non-latin characters
PARSED <- htmlParse(SOURCE)
links <- (xpathSApply(PARSED, "//a/@href"))
links[grep("pdf",links)][1]
links <- paste0("http://lib.ru",links[grep("pdf",links)])
links[1]
```
Can you write a loop to download the first ten links?
Solutions
========================
```{r eval=F }
for (i in 1:10){
parts <- unlist(str_split(links[i],"/"))
outName <- parts[length(parts)]
print(outName)
download.file(links[i],outName)
}
```
String manipulation in R
==============
type:sq2
Hardest part of task above: meaningful filenames
Done using str_split
Top string manipulation functions:
- grep
- gsub
- str_split (library: stringr)
- paste
- nchar
- tolower (also toupper, capitalize)
- str_trim (library: stringr)
- Encoding read here
Reading:
- http://en.wikibooks.org/wiki/R_Programming/Text_Processing
- http://chemicalstatistician.wordpress.com/2014/02/27/useful-functions-in-r-for-manipulating-text-data/
What do they do: grep
=====================
type:sq1
Grep + regex: find stuff
```{r}
grep("SHAKESPEARE",links)
links[grep("SHAKESPEARE",links)] #or: grep("SHAKESPEARE",links,value=T)
```
Grep 2
============
type:sq
useful options:
invert=T : get all non-matches
ignore.case=T : what it says on the box
value = T : return values rather than positions
Especially good with regex for partial matches:
```{r}
grep("hamlet*",links,value=T)[1]
```
Regex
========
Check out
- ?regex
- http://www.rexegg.com/regex-quickstart.html
Can match beginning or end of word, e.g.:
```{r}
grep("stalin",c("stalin","stalingrad"),value=T)
grep("stalin\\b",c("stalin","stalingrad"),value=T)
```
What do they do: gsub
=====================
```{r}
author <- "By Rolf Fredheim"
gsub("By ","",author)
gsub("Rolf Fredheim","Tom",author)
```
Gsub can also use regex
str_split
==============
type:sq
- Manipulating URLs
- Editing time stamps, etc
syntax: str_split(inputString,pattern)
returns a list
```{r}
str_split(links[1],"/")
unlist(str_split(links[1],"/"))
```
we wanted the last element (perewody.df):
```{r}
parts <- unlist(str_split(links[1],"/"))
length(parts)
parts[length(parts)]
```
The rest
============
type:sq1
- nchar
- tolower (also toupper)
- str_trim (library: stringr)
```{r}
annoyingString <- "\n something HERE \t\t\t"
```
***
```{r}
nchar(annoyingString)
str_trim(annoyingString)
tolower(str_trim(annoyingString))
nchar(str_trim(annoyingString))
```
Formatting dates
============
type:sq1
Easiest way to read in dates:
```{r}
require(lubridate)
as.Date("2014-01-31")
date <- as.Date("2014-01-31")
str(date)
```
Correctly formatting dates is useful:
***
```{r}
date <- as.Date("2014-01-31")
str(date)
date+years(1)
date-months(6)
date-days(1110)
```
============
type:sq1
the full way to enter dates:
```{r}
as.Date("2014-01-31","%Y-%m-%d")
```
The funny characters preceded by percentage characters denote date formatting
- %Y = 4 digits, 2004
- %y = 2 digits, 04
- %m = month
- %d = day
- %b = month in characters
==============
Most of the time you won't need this. But what about:
```{r}
date <- "04 March 2014"
as.Date(date,"%d %b %Y")
```
Probably worth spelling out, as Brits tend to write dates d-m-y, while Americans prefer m-d-y. Confusions possible for the first 12 days of every month.
Lubridate
========
type:sq
Reading: http://www.r-statistics.com/2012/03/do-more-with-dates-and-times-in-r-with-lubridate-1-1-0/
Lubridate makes this much, much easier:
```{r}
require(lubridate)
date <- "04 March 2014"
dmy(date)
time <- "04 March 2014 16:10:00"
dmy_hms(time,tz="GMT")
time2 <- "2014/03/01 07:44:22"
ymd_hms(time2,tz="GMT")
```
Task
==================
type:sq1
Last week we wrote a scraper for the telegraph:
```{r eval=F}
url <- 'http://www.telegraph.co.uk/news/uknews/terrorism-in-the-uk/10659904/Former-Guantanamo-detainee-Moazzam-Begg-one-of-four-arrested-on-suspicion-of-terrorism.html'
SOURCE <- getURL(url,encoding="UTF-8")
PARSED <- htmlParse(SOURCE)
title <- xpathSApply(PARSED, "//h1[@itemprop='headline name']",xmlValue)
author <- xpathSApply(PARSED, "//p[@class='bylineBody']",xmlValue)
```
author: "\r\n\t\t\t\t\t\t\tBy Miranda Prynne, News Reporter"
time: "1:30PM GMT 25 Feb 2014"
With the functions above, rewrite the scraper to correctly format the dates
Blank slide
==============
Possible solution
===================
type:sq1
```{r}
author <- "\r\n\t\t\t\t\t\t\tBy Miranda Prynne, News Reporter"
a1 <- str_trim(author)
a2 <- gsub("By ","",a1)
a3 <- unlist(str_split(a2,","))[1]
a3
time <- "1:30PM GMT 25 Feb 2014"
t <- unlist(str_split(time,"GMT "))[2]
dmy(t)
```
Intro to APIs
=======================
type:sq1
Last week we looked at the Guardian's social media buttons:
How?
============
- Loop and rbind
- sapply
- sink into database
sqlite in R: http://sandymuspratt.blogspot.co.uk/2012/11/r-and-sqlite-part-1.html
Loop
==============
type:sq
```{r}
require(RCurl)
require(XML)
urls <- c("http://www.bbc.co.uk/news/business-26414285","http://www.bbc.co.uk/news/uk-26407840","http://www.bbc.co.uk/news/world-asia-26413101","http://www.bbc.co.uk/news/uk-england-york-north-yorkshire-26413963")
results=NULL
for (url in urls){
newEntry <- bbcScraper(url)
results <- rbind(results,newEntry)
}
data.frame(results) #ignore the warning
```
Still to do: fix column names
Disadvantage of loop
=====================
type:sq2
left:80
copying data this way is inefficient:
```{r}
temp=NULL
#1st loop
temp <- rbind(temp,results[1,])
temp
#2nd loop
temp <- rbind(temp,results[2,])
#3d loop
temp <- rbind(temp,results[3,])
#4th loop
temp <- rbind(temp,results[4,])
temp
```
=============
In each case we are copying the whole table in order to add a single line.
- this is slow
- need to keep two copied in memory (means we can only ever use at most half of computer's RAM)
sapply
===========
A bit more efficient.
Takes a vector.
Applies a formula to each item in the vector:
```{r}
dat <- c(1,2,3,4,5)
sapply(dat,function(x) x*2)
```
syntax: sapply(data,function)
function: can be your own function, or a standard one:
```{r}
sapply(dat,sqrt)
```
in our case:
========================
type:sq
```{r}
urls <- c("http://www.bbc.co.uk/news/business-26414285","http://www.bbc.co.uk/news/uk-26407840","http://www.bbc.co.uk/news/world-asia-26413101","http://www.bbc.co.uk/news/uk-england-york-north-yorkshire-26413963")
sapply(urls,bbcScraper)
```
we don't really want the data in this format. We can reshape it, or use a related function:
=================
ldply: For each element of a list, apply function then combine results into a data frame.
```{r}
require(plyr)
dat <- ldply(urls,bbcScraper)
dat
```
Task
===============
type:section
- Scrape ten BBC news articles
- Put them in a data frame
Link harvesting
====================
Entering URLs by hand is tedious
We can speed this up by automating the collection of links
How can we find relevant links?
- ?
- Scraping URLs in a search result
- those on the front page
Search result
============
Go to page, make a search, repeat that query in R
Press next page to get pagination pattern. E.g:
http://www.bbc.co.uk/search/news/?page=2&q=Russia
Task
==========
type:section
Can you collect the links from that page?
Can you restrict it to the search results (find the right div)
One solution
================
type:sq1
All links
```{r results="hide"}
url="http://www.bbc.co.uk/search/news/?page=3&q=Russia"
SOURCE <- getURL(url,encoding="UTF-8")
PARSED <- htmlParse(SOURCE)
xpathSApply(PARSED, "//a/@href")
```
filtered links:
```{r results="hide"}
unique(xpathSApply(PARSED, "//a[@class='title linktrack-title']/@href"))
#OR xpathSApply(PARSED, "//div[@id='news content']/@href")
```
Why 'unique'?
Another option: xpathSApply(PARSED, "//div[@id='news content']/@href")
Create a table
=====================
type:sq1
```{r}
require(plyr)
targets <- unique(xpathSApply(PARSED, "//a[@class='title linktrack-title']/@href"))
results <- ldply(targets[1:5],bbcScraper) #limiting it to first five pages
results
```
Scale up further
==============
Account for pagination by writing a scraper that searches:
http://www.bbc.co.uk/search/news/?page=3&q=Russia
http://www.bbc.co.uk/search/news/?page=4&q=Russia
http://www.bbc.co.uk/search/news/?page=5&q=Russia
etc.
hint: use paste or paste0
Let's not do this in class though, and give the BBC's servers some peace
Copyright
======================
type:sq
Reading
- http://about.bloomberglaw.com/practitioner-contributions/legal-issues-raised-by-the-use-of-web-crawling-and-scraping-tools-for-analytics-purposes/
- http://www.theguardian.com/media-tech-law/tangled-web-of-copyright-law
- http://matthewsag.com/googlebooks-decision-fair-use/
- http://www.bbc.co.uk/news/technology-26187730
- http://matthewsag.com/anotherbestpracitcescode/
- http://www.ipo.gov.uk//response-2011-copyright-final.pdf
- http://www.arl.org/storage/documents/publications/code-of-best-practices-fair-use.pdf
> One case involved an online activist who scraped the MIT website and ultimately downloaded millions of academic articles. This guy is now free on bond, but faces dozens of years in prison and $1 million if convicted.
===================
> PubMed Central UK has strong provisions against automated and systematic download of articles: Crawlers and other automated processes may NOT be used to systematically retrieve batches of articles from the UKPMC web site. Bulk downloading of articles from the main UKPMC web site, in any way, is prohibited because of copyright restrictions.
--http://www.technollama.co.uk/wp-content/uploads/2013/04/Data-Mining-Paper.pdf
Rough guidelines
=======================
type:sq
I don't know IP law. So all the below are no more than guidelines
Most legal cases relate to copying and republishing of information for profit (see article1 above)
- Don't cause damage (through republishing, taking-down servers, prevention of profit)
- Make sure your use is 'transformative'
- Read the TOCs
In 2013 Google Books was found to be 'fair use'
- Judgement good news for scholars and libraries
Archiving and downloading
- databases can be used to 'facilitate non-consumptive research'
Distinction made between freely available content, and that behind a pay-wall, requiring to accept conditions, etc.
Downloading
===========
type:sq
Don't download loads of journal articles. Just don't
If you need/want to download something requiring authentication, be careful.
-attach cookie
Packages: httr
Many resources on how to do this, many situations in which this is totally OK. It is not hard, but often quite shady. If you need this for your work, consider the explanations below, and exercise restraint.
- http://stackoverflow.com/questions/13204503
- http://stackoverflow.com/questions/10213194
- http://stackoverflow.com/questions/16118140
- http://stackoverflow.com/questions/15853204
- http://stackoverflow.com/questions/19074359
- http://stackoverflow.com/questions/8510528
- http://stackoverflow.com/questions/9638451
- http://stackoverflow.com/questions/2388974
Principles of downloading
=====================
Function: download.file(url,destfile)
destfile = filename on disk
option: mode="wb"
Often files downloaded are corrupted. Setting mode ="wb" prevents "\n" causing havoc, e.g. with image files
Example
===============
http://lib.ru
Library of Russian language copyright-free works. (like Gutenberg)
This is a 1747 translation of Hamlet into Russian
Run this in your terminal:
```{r, eval=F}
url <- "http://lib.ru/SHAKESPEARE/hamlet8.pdf"
download.file(url,"hamlet.pdf",mode="wb")
```
navigate to your working directory, and you should have the pdf there
Automating downloads
=================
type:sq1
As with the newspaper articles, downloads are facilitated by getting the right links. Let's search for pdf files and download the first ten results:
```{r}
url <- "http://lib.ru/GrepSearch?Search=pdf"
SOURCE <- getURL(url,encoding="UTF-8") # Specify encoding when dealing with non-latin characters
PARSED <- htmlParse(SOURCE)
links <- (xpathSApply(PARSED, "//a/@href"))
links[grep("pdf",links)][1]
links <- paste0("http://lib.ru",links[grep("pdf",links)])
links[1]
```
Can you write a loop to download the first ten links?
Solutions
========================
```{r eval=F }
for (i in 1:10){
parts <- unlist(str_split(links[i],"/"))
outName <- parts[length(parts)]
print(outName)
download.file(links[i],outName)
}
```
String manipulation in R
==============
type:sq2
Hardest part of task above: meaningful filenames
Done using str_split
Top string manipulation functions:
- grep
- gsub
- str_split (library: stringr)
- paste
- nchar
- tolower (also toupper, capitalize)
- str_trim (library: stringr)
- Encoding read here
Reading:
- http://en.wikibooks.org/wiki/R_Programming/Text_Processing
- http://chemicalstatistician.wordpress.com/2014/02/27/useful-functions-in-r-for-manipulating-text-data/
What do they do: grep
=====================
type:sq1
Grep + regex: find stuff
```{r}
grep("SHAKESPEARE",links)
links[grep("SHAKESPEARE",links)] #or: grep("SHAKESPEARE",links,value=T)
```
Grep 2
============
type:sq
useful options:
invert=T : get all non-matches
ignore.case=T : what it says on the box
value = T : return values rather than positions
Especially good with regex for partial matches:
```{r}
grep("hamlet*",links,value=T)[1]
```
Regex
========
Check out
- ?regex
- http://www.rexegg.com/regex-quickstart.html
Can match beginning or end of word, e.g.:
```{r}
grep("stalin",c("stalin","stalingrad"),value=T)
grep("stalin\\b",c("stalin","stalingrad"),value=T)
```
What do they do: gsub
=====================
```{r}
author <- "By Rolf Fredheim"
gsub("By ","",author)
gsub("Rolf Fredheim","Tom",author)
```
Gsub can also use regex
str_split
==============
type:sq
- Manipulating URLs
- Editing time stamps, etc
syntax: str_split(inputString,pattern)
returns a list
```{r}
str_split(links[1],"/")
unlist(str_split(links[1],"/"))
```
we wanted the last element (perewody.df):
```{r}
parts <- unlist(str_split(links[1],"/"))
length(parts)
parts[length(parts)]
```
The rest
============
type:sq1
- nchar
- tolower (also toupper)
- str_trim (library: stringr)
```{r}
annoyingString <- "\n something HERE \t\t\t"
```
***
```{r}
nchar(annoyingString)
str_trim(annoyingString)
tolower(str_trim(annoyingString))
nchar(str_trim(annoyingString))
```
Formatting dates
============
type:sq1
Easiest way to read in dates:
```{r}
require(lubridate)
as.Date("2014-01-31")
date <- as.Date("2014-01-31")
str(date)
```
Correctly formatting dates is useful:
***
```{r}
date <- as.Date("2014-01-31")
str(date)
date+years(1)
date-months(6)
date-days(1110)
```
============
type:sq1
the full way to enter dates:
```{r}
as.Date("2014-01-31","%Y-%m-%d")
```
The funny characters preceded by percentage characters denote date formatting
- %Y = 4 digits, 2004
- %y = 2 digits, 04
- %m = month
- %d = day
- %b = month in characters
==============
Most of the time you won't need this. But what about:
```{r}
date <- "04 March 2014"
as.Date(date,"%d %b %Y")
```
Probably worth spelling out, as Brits tend to write dates d-m-y, while Americans prefer m-d-y. Confusions possible for the first 12 days of every month.
Lubridate
========
type:sq
Reading: http://www.r-statistics.com/2012/03/do-more-with-dates-and-times-in-r-with-lubridate-1-1-0/
Lubridate makes this much, much easier:
```{r}
require(lubridate)
date <- "04 March 2014"
dmy(date)
time <- "04 March 2014 16:10:00"
dmy_hms(time,tz="GMT")
time2 <- "2014/03/01 07:44:22"
ymd_hms(time2,tz="GMT")
```
Task
==================
type:sq1
Last week we wrote a scraper for the telegraph:
```{r eval=F}
url <- 'http://www.telegraph.co.uk/news/uknews/terrorism-in-the-uk/10659904/Former-Guantanamo-detainee-Moazzam-Begg-one-of-four-arrested-on-suspicion-of-terrorism.html'
SOURCE <- getURL(url,encoding="UTF-8")
PARSED <- htmlParse(SOURCE)
title <- xpathSApply(PARSED, "//h1[@itemprop='headline name']",xmlValue)
author <- xpathSApply(PARSED, "//p[@class='bylineBody']",xmlValue)
```
author: "\r\n\t\t\t\t\t\t\tBy Miranda Prynne, News Reporter"
time: "1:30PM GMT 25 Feb 2014"
With the functions above, rewrite the scraper to correctly format the dates
Blank slide
==============
Possible solution
===================
type:sq1
```{r}
author <- "\r\n\t\t\t\t\t\t\tBy Miranda Prynne, News Reporter"
a1 <- str_trim(author)
a2 <- gsub("By ","",a1)
a3 <- unlist(str_split(a2,","))[1]
a3
time <- "1:30PM GMT 25 Feb 2014"
t <- unlist(str_split(time,"GMT "))[2]
dmy(t)
```
Intro to APIs
=======================
type:sq1
Last week we looked at the Guardian's social media buttons:
 How do these work?
http://www.theguardian.com/world/2014/mar/03/ukraine-navy-officers-defect-russian-crimea-berezovsky
Go to source by right-clicking, select view page source, and go to line 368
Open this javascript in a new browser window
About twenty lines down there is the helpful comment:
> Look for facebook share buttons and get share count from Facebook GraphAPI
This is followed by some JQuery statements and an ajax call
Ajax
==================
From Wikipedia:
> With Ajax, web applications can send data to, and retrieve data from, a server asynchronously (in the background) without interfering with the display and behavior of the existing page. Data can be retrieved using the XMLHttpRequest object. Despite the name, the use of XML is not required (JSON is often used instead.
How does this work?
================
- You load the webpage
- There is a script in the code.
- As well as placeholders, empty fields
- The script runs, and executes the Ajax call.
- This connects, in this case, with the Facebook API
- the API returns data about the page from Facebook's servers
- The JQuery syntax interprets the JSON and fills the blanks in the html
- The user sees the number of shares.
Problem: when we download the page, we see only the first three steps.
Solution: intercept the Ajax call, or, go straight to the source
APIs
================
type:sq1
> When used in the context of web development, an API is typically defined as a set of Hypertext Transfer Protocol (HTTP) request messages, along with a definition of the structure of response messages, which is usually in an Extensible Markup Language (XML) or JavaScript Object Notation (JSON) format.
> The practice of publishing APIs has allowed web communities to create an open architecture for sharing content and data between communities and applications. In this way, content that is created in one place can be dynamically posted and updated in multiple locations on the web
-Wikipedia
All the social buttons script is doing is accessing, in turn, the Facebook, the Twitter, Google, Pinterest and Linkedin APIs, collecting data, and pasting that into the website
How does this work
==================
Here is the javascript code:
> var fqlQuery = 'select share_count,like_count from link_stat where url="' + url + '"'
> queryUrl = 'http://graph.facebook.com/fql?q='+fqlQuery+'&callback=?';
Can we work with that? You bet.
Code translated to R:
=================
type:sq1
```{r}
fqlQuery='select share_count,like_count,comment_count from link_stat where url="'
url="http://www.theguardian.com/world/2014/mar/03/ukraine-navy-officers-defect-russian-crimea-berezovsky"
queryUrl = paste0('http://graph.facebook.com/fql?q=',fqlQuery,url,'"') #ignoring the callback part
lookUp <- URLencode(queryUrl) #What do you think this does?
lookUp
```
Paste that into your browser (lose the quotation marks!), and what do we find....?
Retrieving data
==============
type:sq
Our old pal JSON. This should look familiar by now
Why not try it for a few other articles: this works for any url.
Here's how to check the stats for the slides from our first session:
```{r}
require(rjson)
url="http://quantifyingmemory.blogspot.com/2014/02/web-scraping-basics.html"
queryUrl = paste0('http://graph.facebook.com/fql?q=',fqlQuery,url,'"') #ignoring the callback part
lookUp <- URLencode(queryUrl)
rd <- readLines(lookUp, warn="F")
dat <- fromJSON(rd)
dat
```
Accessing the numbers
=========
type:sq1
Here's how we grab the numbers from the list
```{r}
dat$data[[1]]$like_count
dat$data[[1]]$share_count
dat$data[[1]]$comment_count
```
Pretty modest.
task
======================
type:section
If there's any time left in class, why not:
- write a scraper to find which of the articles from the BBC earlier have been shared the most.
Finally
==================
type:sq
APIs are really useful: we don't (normally!) have to worry about terms of use
Next week I'll bring a few along, and we'll spend most of class looking at writing scrapers for them.
Examples:
- Maps
- Cricket scores
- YouTube
- Lyrics
- Weather
- Stock market (ticker) info
- etc. etc.
How do these work?
http://www.theguardian.com/world/2014/mar/03/ukraine-navy-officers-defect-russian-crimea-berezovsky
Go to source by right-clicking, select view page source, and go to line 368
Open this javascript in a new browser window
About twenty lines down there is the helpful comment:
> Look for facebook share buttons and get share count from Facebook GraphAPI
This is followed by some JQuery statements and an ajax call
Ajax
==================
From Wikipedia:
> With Ajax, web applications can send data to, and retrieve data from, a server asynchronously (in the background) without interfering with the display and behavior of the existing page. Data can be retrieved using the XMLHttpRequest object. Despite the name, the use of XML is not required (JSON is often used instead.
How does this work?
================
- You load the webpage
- There is a script in the code.
- As well as placeholders, empty fields
- The script runs, and executes the Ajax call.
- This connects, in this case, with the Facebook API
- the API returns data about the page from Facebook's servers
- The JQuery syntax interprets the JSON and fills the blanks in the html
- The user sees the number of shares.
Problem: when we download the page, we see only the first three steps.
Solution: intercept the Ajax call, or, go straight to the source
APIs
================
type:sq1
> When used in the context of web development, an API is typically defined as a set of Hypertext Transfer Protocol (HTTP) request messages, along with a definition of the structure of response messages, which is usually in an Extensible Markup Language (XML) or JavaScript Object Notation (JSON) format.
> The practice of publishing APIs has allowed web communities to create an open architecture for sharing content and data between communities and applications. In this way, content that is created in one place can be dynamically posted and updated in multiple locations on the web
-Wikipedia
All the social buttons script is doing is accessing, in turn, the Facebook, the Twitter, Google, Pinterest and Linkedin APIs, collecting data, and pasting that into the website
How does this work
==================
Here is the javascript code:
> var fqlQuery = 'select share_count,like_count from link_stat where url="' + url + '"'
> queryUrl = 'http://graph.facebook.com/fql?q='+fqlQuery+'&callback=?';
Can we work with that? You bet.
Code translated to R:
=================
type:sq1
```{r}
fqlQuery='select share_count,like_count,comment_count from link_stat where url="'
url="http://www.theguardian.com/world/2014/mar/03/ukraine-navy-officers-defect-russian-crimea-berezovsky"
queryUrl = paste0('http://graph.facebook.com/fql?q=',fqlQuery,url,'"') #ignoring the callback part
lookUp <- URLencode(queryUrl) #What do you think this does?
lookUp
```
Paste that into your browser (lose the quotation marks!), and what do we find....?
Retrieving data
==============
type:sq
Our old pal JSON. This should look familiar by now
Why not try it for a few other articles: this works for any url.
Here's how to check the stats for the slides from our first session:
```{r}
require(rjson)
url="http://quantifyingmemory.blogspot.com/2014/02/web-scraping-basics.html"
queryUrl = paste0('http://graph.facebook.com/fql?q=',fqlQuery,url,'"') #ignoring the callback part
lookUp <- URLencode(queryUrl)
rd <- readLines(lookUp, warn="F")
dat <- fromJSON(rd)
dat
```
Accessing the numbers
=========
type:sq1
Here's how we grab the numbers from the list
```{r}
dat$data[[1]]$like_count
dat$data[[1]]$share_count
dat$data[[1]]$comment_count
```
Pretty modest.
task
======================
type:section
If there's any time left in class, why not:
- write a scraper to find which of the articles from the BBC earlier have been shared the most.
Finally
==================
type:sq
APIs are really useful: we don't (normally!) have to worry about terms of use
Next week I'll bring a few along, and we'll spend most of class looking at writing scrapers for them.
Examples:
- Maps
- Cricket scores
- YouTube
- Lyrics
- Weather
- Stock market (ticker) info
- etc. etc.