Web Scraping
Rolf Fredheim
University of Cambridge
27/05/2014
- What is Web Scraping
- Challenges for scraping with R
- Two examples

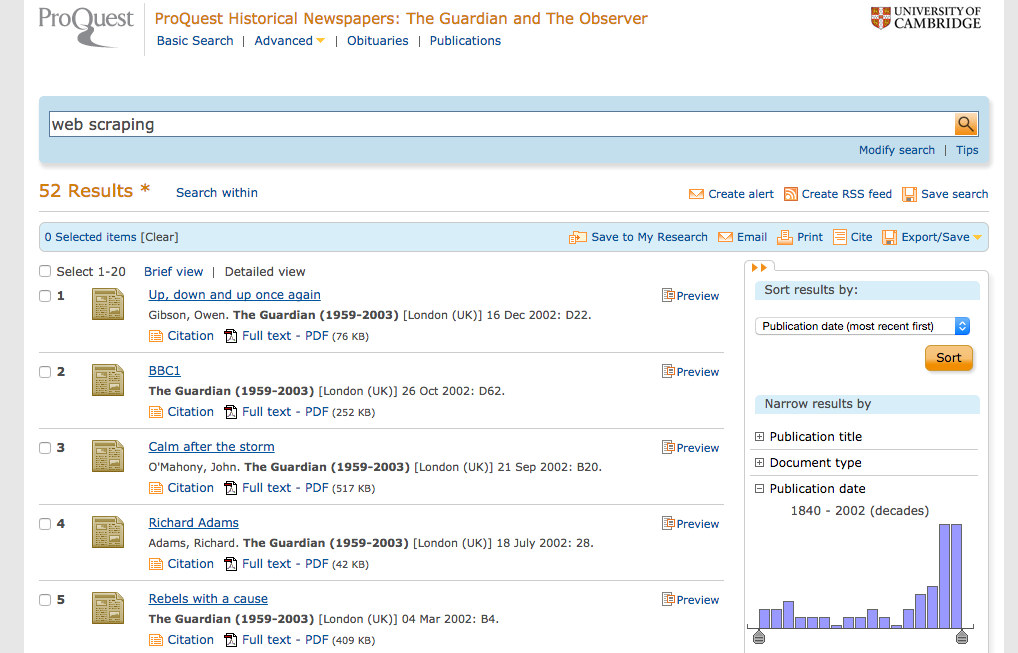
Proquest

Using a scraper
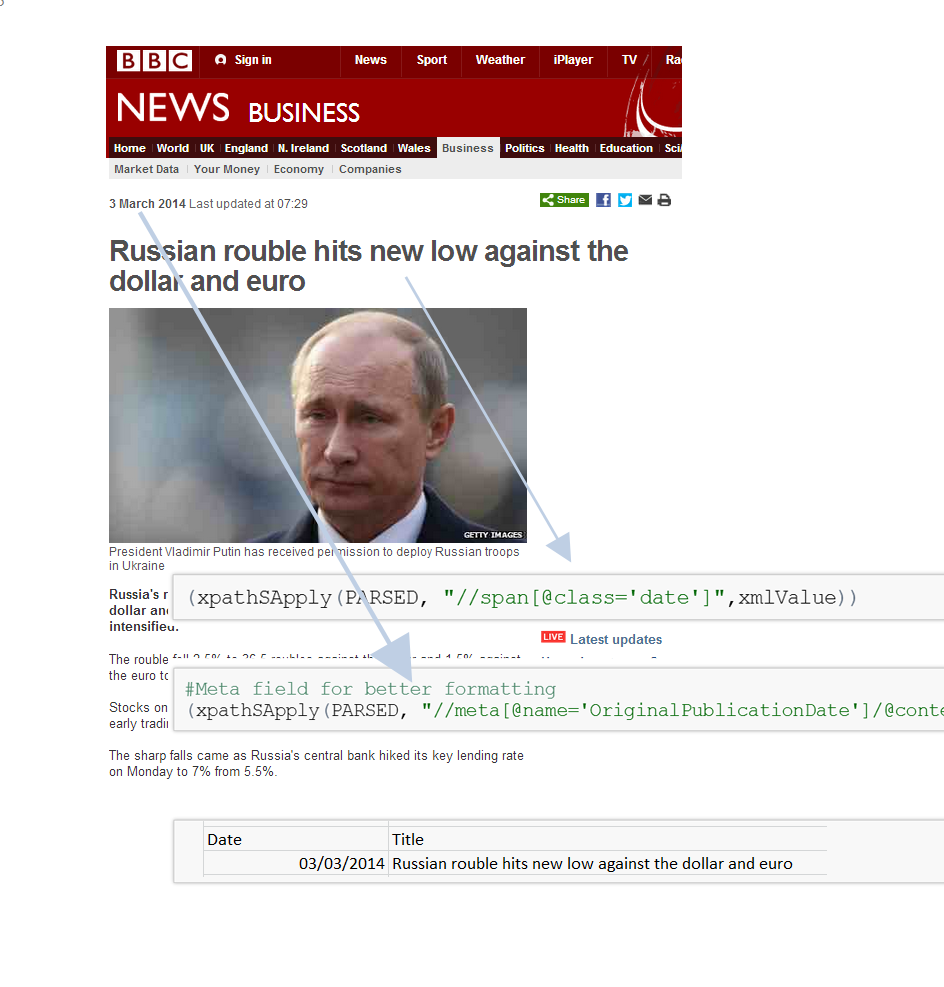
In code
bbcScraper <- function(url){
require(RCurl)
require(XML)
SOURCE <- getURL(url,encoding="UTF-8")
PARSED <- htmlParse(SOURCE,encoding="UTF-8")
title=xpathSApply(PARSED, "//h1[@class='story-body__h1']",xmlValue)
date=as.character(xpathSApply(PARSED, "//div[@class='date date--v2']",xmlValue))[1]
return(c(title,date))
}
url = 'http://www.bbc.co.uk/news/business-26414285'
bbcScraper(url)
[1] "Russian rouble hits new low against the dollar and euro"
[2] "3 March 2014"
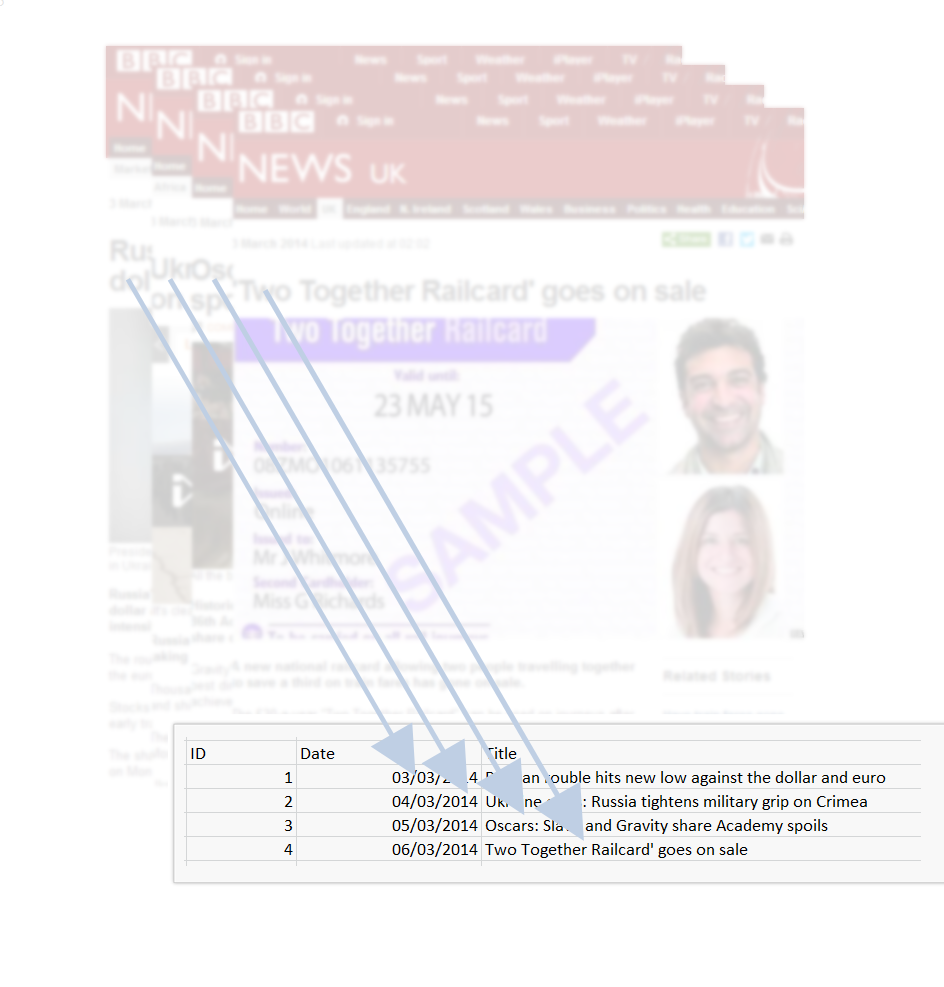
Loop
urls <- c("http://www.bbc.co.uk/news/business-26414285",
"http://www.bbc.co.uk/news/uk-26407840",
"http://www.bbc.co.uk/news/world-asia-26413101",
"http://www.bbc.co.uk/news/uk-england-york-north-yorkshire-26413963")
results=NULL
for (url in urls){
newEntry <- bbcScraper(url)
results <- rbind(results,newEntry)
}
data.frame(results)
X1 X2
1 Russian rouble hits new low against the dollar and euro 3 March 2014
2 'Two Together Railcard' goes on sale 3 March 2014
3 Australia: Snake eats crocodile after battle 3 March 2014
4 Missing Megan Roberts: Police find body in River Ouse 3 March 2014
Getting links
Figure it out:
Or scrape search results
Challenges for scraping with R
- Loops
- Error handling (clunky tryCatch)
- Run in memory
- Nested objects
- Hard to run parallel processes.
- Hard to catch dynamic content, e.g. loaded by Ajax
- Hard(er) to submit login credentials
- Processes rarely run in base R (hard to interrupt or control)
API Examples:
- Social shares, e.g. Facebook, Twitter
- Maps
- Cricket scores
- YouTube
- Lyrics
- Weather
- Comments on articles
- Stock market (ticker) info
Juicer API
- Can be installed locally
- Extracts article metadata (Goose)
- Does named entity extraction (Stanford NER)
- Yields JSON object
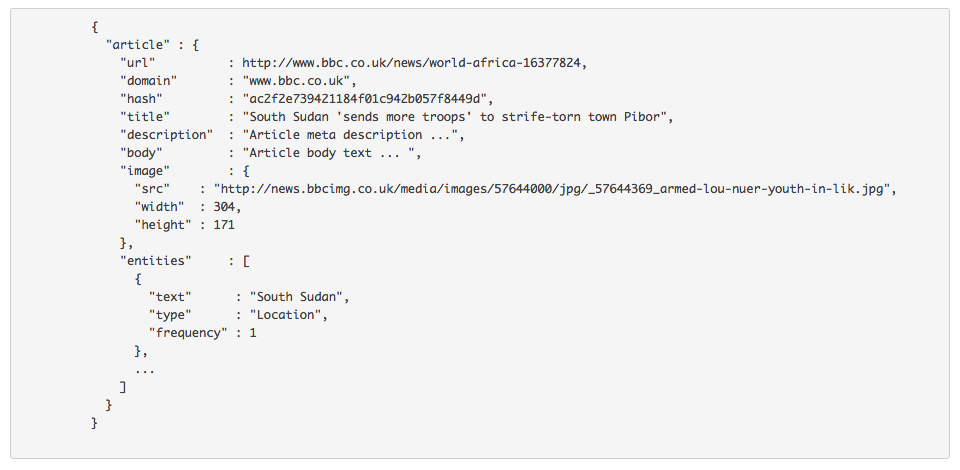
JSON -> database
require(RMongo)
require(RCurl)
require(plyr)
mongo_in <- mongoDbConnect("dbName",host='0.0.0.0',port=27017)
url <- 'http://www.huffingtonpost.com/2015/02/22/wisconsin-right-to-work_n_6731064.html'
api <- 'http://juicer.herokuapp.com/api/article?url='
target <- paste(api,url,sep="")
SOURCE <- getURL(target,encoding="UTF-8")
dbInsertDocument(mongo_in, 'collectionName',SOURCE)
saveOne <- function(url){
api <- 'http://juicer.herokuapp.com/api/article?url='
target <- paste(api,url,sep="")
SOURCE <- getURL(target,encoding="UTF-8")
dbInsertDocument(mongo_in, 'collectionName',SOURCE)
}
urls=c(
'http://www.huffingtonpost.com/2015/02/22/wisconsin-right-to-work_n_6731064.html',
'http://www.theguardian.com/commentisfree/2015/jan/04/internet-freedom-china-russia-us-google-microsoft-digital-sovereignty',
'http://www.bbc.co.uk/news/business-32895827'
)
lapply(urls,saveOne)
{ “title” : “Who’s the true enemy of internet freedom - China, Russia, or the US?” } { “title” : “Wisconsin Could Be Right-To-Work In A Matter Of Days” } { “title” : “Aer Lingus shares up as Irish government backs stake sale” }